Reflexive Adaptation
Introduction
My most recent research work dealt with Artificial Intelligence (AI) for online adaptation in autonomous systems, and was part of a DARPA-funded initiative towards advancing research in lifelong learning agents. This work was done in collaboration with an international team involving several other universities and research institutions. Here, the context is autonomous, online learning. While many examples exist that demonstrate the ability to "teach" an agent, offline, to expertly perform a specific task, the ability of an AI agent to automatically learn to perform new and varied tasks online still poses significant challenges and is an active area of research.
Having the ability to learn and adapt online to unforeseen variations during deployment, without the need to be taken offline for additional training, would greatly enhance an autonomous agent's versatility and overall usefulness. This is particularly true when the intent is to deploy the agent in complex environments for an extended period of time (e.g., an autonomous driving car) where frequent task variations, or unexpected environmental changes, can occur.
When such changes occur during deployment, the agent must adapt and learn to function effectively through its experiences obtained from exploring and interacting with its surroundings. As it takes particular actions based on its current state and that of its environment, it experiences the corresponding consequences. Each time a meaningful consequence occurs, it represents an opportunity for the agent to learn and improve its performance.
However, with this exploration of the unfamiliar in order to adapt to a change or learn a new task also come risks. Actions based on what the agent has learned previously may now be sub-optimal, and any models it has of the environment may be unreliable or inapplicable. Online performance can, thus, be expected to drop as the agent enters a recovery phase to try to learn and improve, as illustrated in Figure 1. It is during this performance-drop and gradual-improvement stage that the agent is vulnerable, due to its liability to take potentially dangerous actions. With a compromised ability to have accurate foresight of the impact of its actions, the agent may quickly find itself in an emergency situation with little time to devise an effective response (using its current policy) to avoid a potentially catastrophic event. This is of particular concern in safety-critical applications where incorrect actions in a given situation could lead to damage or destruction of the agent, or even loss of human life.

Figure 1: A change in task and/or environmental conditions during deployment would constitute a surprise event for the agent that would inevitably lead to a performance drop until the agent has had a chance to explore anew and gradually improve its performance once again. An agent that does not have the capability to learn new tasks or adapt online will experience a permanent performance drop (orange curve). A lifelong learning agent with online-learning ability will show a temporary drop in performance, which gradually increases over time (green curve). However, this period of low performance directly after the unexpected event can correspond to dangerous actions taken by the agent that can lead to potentially catastrophic events. By taking over the agent's intended exploratory actions with a short-term, emergency response, customized to the particular emergency situation encountered, one effectively reduces the depth of this performance drop (blue curve).
With this scenario as motivation, the objective of our research was to develop a type of emergency-management system for lifelong learning agents, akin to the reflexive abilities that are innate to humans and animals that help them to minimize harm in certain treacherous situations (e.g., the way we quickly move our arms out in front of us when we suddenly trip and begin to fall, or the way our eyelids suddenly shut close when we perceive an airborne object flying towards our eyes). This work focused on Reinforcement Learning (RL) agents, as the overall lifelong learning system being developed by our larger research team employed an RL framework.
Recent advances and state-of-the-art methods for RL in the literature, particularly those leveraging deep neural networks, have shown promising results in developing autonomous agents that learn to effectively interact with their environments in a number of different application domains. These approaches work well in situations where it can be assumed that all the events encountered during deployment arise from the same distribution on which the agent has been trained. However, agents that must function within complex, real-world environments for an extended period of time can be subjected to unexpected circumstances outside of the distribution they have been designed for or trained on, due to environmental changes that arise.
While there are also continual learning approaches that retrain agents online to eventually improve performance on novel events (i.e., as illustrated by the green curve in Figure 1), they require a significant amount of time and repeated encounters with those events before learning the optimal behavior that covers those cases. If these novel events represent dangerous situations in safety-critical applications, this still leaves the question of how to respond to these events in the interim. Hence, our research group's contribution to this overall lifelong learning system project was the development of a data-driven, emergency-response-generation method that allows an agent to deal with novel situations in the short-term, without reliance on the accuracy of existing models or the validity of safe states and recovery policies developed offline or from past experiences.
The key insight to our approach is that uncertainty in observations from the environment can be used as a driver for the generation of effective, short-term responses online, when necessary, to circumvent dangers, so that the agent can continue to function and learn within its environment. We investigated, therefore, how the minimization of a measure of observation uncertainty could be correlated with safe and effective actions in situations where an online-learning agent's existing policy would fail. While the use of uncertainty to detect potential danger is not new, using it to generate actions in an online manner, customized to the particular never-before-seen emergency as it unfolds, is novel.
In the context of autonomous AI agents, these reflexive responses would be sequences of actions over a short time-span to circumvent a catastrophic event. They are intended to be low-level processes that are triggered automatically, only in case of emergency, and can be overridden by a higher-level process if needed. We refer to this approach to safe exploration for lifelong learning agents as the Autonomous Emergency Management System (A-EMS). Of course, as the agent begins to explore and learn its new task/environment better, it is expected that its reliance on the A-EMS module should gradually decrease as fewer and fewer emergencies will be triggered.
Reflexive adaptation ability in an autonomous agent can have an impact on safety as well as adaptability. From the perspective of safety, reflexes can help an agent avoid an emergency situation that could lead to catastrophic failure (e.g., a mobile robot avoiding collision with an unexpected dynamic obstacle that suddenly moves into its path), thereby reducing the downtime and expense associated with frequent repair or even reconstruction. In an application such as autonomous driving cars, for example, a properly generated reflexive response could also mean avoiding striking a pedestrian, thereby saving a life. From the perspective of adaptation, avoiding catastrophic events allows an RL agent to survive for longer periods of time in its environment, and to thus continue to be exposed to, and benefit from, new and varied learning experiences. This has the effect of expediting the re-learning of the optimal policy to address the environmental change or the new task that the agent is presented with.
Problem Description
We consider a problem scenario where a trained agent encounters an unforeseen situation during deployment that renders its existing policy highly unreliable, so that any inferences based on its existing environment models, as well as any pre-defined safe state/action regions, are no longer valid for safe decision-making. The agent's standard learning process is then engaged and it begins to search for the optimal policy to account for the new task or environmental change. We can envision the standard learning scenario as that shown in Figure 2. Here, the environment provides observation data with each time-step. A reinforcement learning algorithm would be in place that takes these observations as input, along with the corresponding rewards and actions taken in the previous time-step, to train the policy network to take the best actions for a given environment state. In this way, with each time-step, the policy is gradually updated, and learns to provide (ideally) better actions for given observations.

Figure 2: Typical reinforcement learning scenario.
The A-EMS method is considered to be part of an independent module that must monitor the observations coming from the environment, as well as the intended actions by the policy, at every time-step of the main policy training process. It lays dormant, continuously analyzing this information, and only springs into action if it determines that an emergency situation is imminent from the observations rolling out and the actions being taken. In such a situation it devises an appropriate emergency response and intervenes in the main training loop by taking-over the actions being applied to the environment by the policy and replacing them with the actions of the generated response, for the duration of the planned action-sequence.
As illustrated in Figure 3, this problem scenario gives rise to two key sub-problems that need to be addressed:
1) Emergency Detection: where the incoming stream of observations and actions are analyzed to predict whether or not an emergency situation is imminent;
2) Response Generation: where an effective reflex action-sequence is generated, online, customized to the particular emergency encountered.
The response devised is an action-sequence implemented over the next N discrete time-steps to address the danger. This action-sequence must be generated online as the encounter with the novel situation unfolds.

Figure 3: Flowchart of overall approach to reflexive adaptation.
Method Overview
The primary contribution of our research work was on the response-generation sub-problem listed above. This is the method by which the response action-sequence is devised after a novel, potentially dangerous situation has been detected. For the purposes of composing a complete monitor-and-takeover module, a mechanism is also required (suitable to the application domain being addressed) that can detect when the agent has encountered a scenario that represents sufficient danger, given how the policy would respond. As numerous approaches to novelty detection can be found in the literature that can be used for this purpose, it is assumed that an emergency detection method is available that monitors the agent during deployment and can identify a novel situation that the agent is unprepared to handle. Nevertheless, for the purposes of demonstration and overall methodology validation, a rudimentary detection method based on analyzing auto-encoder reconstruction errors on camera-image data was devised to address the first sub-problem.
Emergency Detection
The main novelty of the reflexive adaptation system being developed here is that it provides autonomous agents the ability to react to situations that are very different from those it has seen during training or from past experiences. In such situations, both predictive models and policies learned by reinforcement learning cannot be expected to perform appropriately since the observations obtained in these novel situations would fall outside the distribution of the data-set on which these models have been trained. However, as a result, one can also expect that such out-of-distribution observations will be associated with an increase in their corresponding uncertainty. Thus, an uncharacteristic increase in uncertainty can be used as an indicator to detect when a significantly novel situation has occurred. While the accuracy of such an indicator can certainly be improved upon in order to determine whether or not the novel encounter represents danger (e.g., through analysis of the values output by the reward function used by the learning algorithm), for the purposes of demonstration and validation of the response-generation method, it was sufficient to use a rudimentary system for emergency detection that compares the computed uncertainty against a fixed threshold value.
The manner in which observation uncertainty is computed will depend on the nature of the observations obtained. The application domains that were used for experimentation and validation were OpenAI Gym Atari game environments as well as the CARLA autonomous driving car simulation environment [1]. Observations of the environmental state in these domains were in the form of RGB images expressed as 3D image arrays. One issue that arises when working with environments that provide visual data (i.e., image-based observations) to process and analyze is that this input information is high-dimensional and can be unwieldy. In the interest of processing time, data storage requirements, and learning efficiency, we would like to work with a compressed or somehow reduced version of this data. However, it is necessary that this compressed version still be able to properly characterize the state information being received. To address this issue, we opted to use a Variational Auto-Encoder (VAE), which not only allows for a means to compute observation uncertainty, but also forms a key component of the response-generation method, as will be shown later.
A VAE is an artificial neural network designed to perform data-compression. The VAE used in our work is trained to convert an input RGB image (i.e., the observation) into a lower-dimensional data object called a "latent" vector. The structure used for this network is borrowed from [2]. As shown in Figure 4, this VAE employs a deep convolutional neural network in its encoding layers that encodes an image into a latent vector, as well as a deep convolutional neural network in its decoding layers that can take a latent representation and reconstruct the original image from it. For example, in our work, the VAE takes as input a 64x64x3 RGB image from the simulation environment and converts it into a 1x64 vector that serves as an abstract representation of the original state information contained in the image. Given a database of images, the VAE is trained to minimize the error between the original image input to the encoder and the reconstructed image output by the decoder. In so doing, the network learns to construct an accurate, compressed representation through the latent vector that captures only the important information from the input, which is sufficient to reconstruct the original if necessary. More information on this VAE can be found in [2].
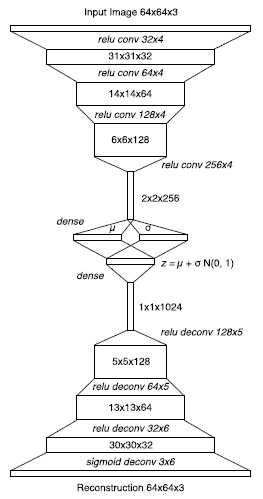
Figure 4: Structure of the variational auto-encoder (taken from [2]).
This VAE is trained on the agent’s past experiences or on a representative environment under some nominal settings during a pre-deployment phase. Given such a network, observation uncertainty was quantified in terms of the reconstruction errors obtained from processing the RGB-image observations through the VAE. During deployment the VAE reconstruction error is computed on every input observation image obtained from the environment. In particular, this error is calculated as the mean squared pixel-value errors between the input observation image and the reconstructed output from the VAE. A finite history of these computed errors is maintained in a database in a first-in-last-out fashion. These errors are continuously analyzed in order to detect an emergency situation.
An upper-bound threshold, ULe, on the reconstruction errors must be specified, above which there is strong reason to believe that the agent has encountered a significantly novel situation. The user is free to establish this threshold as they wish. One possible approach could be to fit the reconstruction errors on the training data to a probability distribution and then compute the corresponding one-sided r% confidence limit, with the user deciding what the level of confidence, r, should be.
The condition for detection is based on estimating the values of reconstruction errors into the short-term future using real-time data. At each time-step during deployment, a regression model is fitted to the last M VAE reconstruction errors saved, which is then extrapolated some K time-steps into the future. A positive detection event occurs if at least the last q extrapolated errors exceed the established threshold, ULe. The user must choose the values for q and K depending on how conservative or liberal one wishes to be when triggering the emergency response.
Response Generation
The key insight underlying our approach is that taking actions that minimize or eliminate the consequent increase in observation uncertainty in a novel, dangerous situation will have the effect of returning the agent to a state of greater familiarity, thereby bringing it back to safety. Once the agent transitions to a more familiar state (i.e., one that its current policy is already capable of handling), its existing policy can once again resume control of the agent's actions.
The response devised by A-EMS for an emergency situation is an action-sequence that spans some user-specified, fixed number of time-steps, N. This response is devised sequentially by analyzing real-time uncertainty data obtained online. The measure of uncertainty used to drive response-generation is the rate of change of reconstruction errors from a VAE that is trained offline under some nominal conditions. Thus, at each time-step of the N-step response, the algorithm must select the action to take that can be expected to minimize the resulting error-rate.
To accomplish this, a modified Bayesian Optimization (BO) framework was adopted. BO is a data-efficient, global-optimization method for sequential decision-making that is ideal for use in situations where the objective function is a black-box, or is expensive to evaluate [3]. It operates by sequentially building a surrogate, probabilistic model of the objective function to be optimized using Gaussian Process (GP) regression [4]. With each time-step, the best action to take is found through an optimization and applied by the agent, and the resulting observation at the next time-step is used to compute the change in VAE reconstruction error. This produces an additional data-point on the objective function, which in-turn is used to revise the GP model. This process then repeats. Thus, with each data-point obtained, the surrogate GP model of the objective function improves. Figure 5 shows a schematic flowchart of the procedure used to determine the best action to take at each time-step.

Figure 5: Workflow of the BO optimization loop executed by the A-EMS method during response-generation (I = observation from environment; e = reconstruction error; a = action; t = time; i = action-sequence time-step index).
In summary, the objective at each time-step, i ∈ [1, N], of the response is to find an action that minimizes the error-rate that would result from that action, by conducting one cycle of the BO loop shown in Figure 5. Thus, the objective function being optimized is the reconstruction error-rate, with the action-vector to be applied being the independent variable. In addition to the last M errors that are always stored in a database, each action and error-rate pair obtained from each step of the emergency response is also saved and used to update the GP regression model. However, rather than trying to optimize the GP model directly, a corresponding, and relatively simpler, heuristic function, termed the "acquisition function", is computed from this model and optimized instead.
The acquisition function quantifies the utility of any given action over the action-vector domain in terms of its potential for finding a better (i.e., lower) objective function value, in a manner that balances exploration (i.e., selecting an action from unexplored regions with greater uncertainty) and exploitation (i.e., selecting an action near prior ones found to give lower error-rates). Several popular choices for this function can be found in the literature [5]. For the purposes of the A-EMS method, the Upper Confidence Bound (UCB) function was chosen, which controls the exploration/exploitation trade-off through the value of a single parameter, β.
The BO loop is designed to gradually transition from an initial exploratory behavior to an exploitative one. In so doing, the optimization intelligently samples the action-space to quickly find and focus on the region most likely to contain the optimal solution, as opposed to trying to build the most accurate overall GP regression model over the entire action-space.
One point of concern in devising the acquisition function is incorporating the influence of time. The underlying relationship between error-rate and actions can, in general, be expected to change with time. Thus, recent observations will have greater relevance to, and influence on, the decision being made at any given time-step compared to older observations. To account for this temporal variation, a penalty function is applied that discounts the utility of any given data-point (as reflected by its corresponding acquisition function value) based on that data-point's age within the time-span of the response action-sequence. However, since the acquisition function is derived from the GP model, these temporal-variation penalties are applied during the computation of the GP regression. In this manner, a reflex action-sequence is created step-by-step to circumvent the imminent danger.
The A-EMS method has been demonstrated in two different simulated 3D autonomous car-driving scenarios: one in which the agent must react to avoid collisions with objects it has never seen before, and another in which the method must react to curtail an unexpected lane-drift induced in the vehicle. However, it should be noted that devising responses based on an abstract notion such as uncertainty-minimization also facilitates employment of this concept in other application domains. More details on the A-EMS method, along with results from the simulation experiments, can be found in the publications corresponding to this research work [6, 7].
[1] A. Dosovitskiy, G. Ros, F. Codevilla, A. Lopez, and V. Koltun, "CARLA: an open urban driving simulator", in Proceedings of the 1st Annual Conference on Robot Learning, Bletchley Park, UK, 2017, pp. 3521–3526.
[2] D. Ha and J. Schmidhuber, "World models", CoRR, 2018, arXiv:1803.10122v4.
[3] J. Mockus, Bayesian Approach to Global Optimization: Theory and Applications, Kluwer Academic, 2013.
[4] C.E. Rasmussen and C.K.I. Williams (eds.), Gaussian Processes for Machine Learning, Cambridge, MA, USA: MIT Press, 2006.
[5] E. Brochu, V. M. Cora, and N. D. Freitas, "A tutorial on bayesian optimization of expensive cost functions, with application to active user modeling and hierarchical reinforcement learning", CoRR, 2010, arXiv:1012.2599v1.
[6] G. Maguire, N. Ketz, P. Pilly, and J.-B. Mouret, "A-EMS: an adaptive emergency management system for autonomous agents in unforeseen situations", 23rd Towards Autonomous Robotic Systems (TAROS 2022) Conference, Abingdon, Oxfordshire, UK, [accepted; in press].
[7] G. Maguire, N. Ketz, P. Pilly, and J.-B. Mouret, "An online data-driven emergency-response method for autonomous agents in unforeseen situations", CoRR, 2021, arXiv:2112.09670.